
大普微实测解析 Windows Server 2025 原生 NVMe 优势
进入 AI 时代,海量数据的并行处理与高频交互需求呈指数级上升。在硬件层面,PCIe 5.0 NVMe SSD 凭借极高的接口带宽与多队列并发机制,已成为现代数据中心应对 I/O 密集型工作负载的核心介质。
然而在实际生产环境中,许多企业级用户面临着一个技术痛点:即便服务器部署了顶级的 PCIe 5.0 NVMe SSD,在面对海量高并发随机 I/O 请求时,应用端实际获取的 I/O 性能往往显著低于硬件的标称峰值。造成这一性能损耗的根源,受限于传统 Windows Server 操作系统历史遗留的存储栈架构设计所带来的高协议转换开销。
随着微软 Windows Server 2025 正式引入原生 NVMe(Native NVMe)支持,这一底层架构局限被打破。
架构演进:从 SCSI 协议转换到原生 NVMe 直达
01.传统架构的性能损耗:双重协议转换
在早期 Windows Server 操作系统中,为保证广泛的硬件兼容性,所有上层的 I/O 请求均需先被翻译为标准的 SCSI 命令,再由微型端口驱动(Miniport)进行二次翻译,重新封装为 NVMe 指令下发至设备。具体环节:
- 第一重协议转换(逻辑驱动层):通用 I/O 请求进入 Disk.sys,被强制翻译为标准的 SCSI 命令。
- 指令路由(端口驱动层):存储端口驱动 Storport.sys 接收该 SCSI 命令,并将其路由至对应的微型端口驱动(Miniport)。
- 第二重协议重构(微型端口驱动层):微型端口驱动(如处理 NVMe 设备的 Stornvme.sys)将接收到的 SCSI 命令进行二次翻译,重新封装为底层硬件能够原生识别的 NVMe 指令,最终下发至设备。
在面对现代 PCIe 5.0 SSD 数百万 IOPS 的极限并发时,这种“通用 I/O -> SCSI -> NVMe”的双重转换机制会产生极高的内核态 CPU 开销 。这导致主机 CPU 算力提前透支,指令下发速率严重滞后于 SSD 的吞吐上限,使得底层硬件无法发挥出真实性能潜能。
02.原生架构的效率革新:端到端直接分发
为解决上述因协议转换引发的性能瓶颈,Windows Server 2025 重构了底层存储架构,摒弃了传统的 SCSI 抽象层,专为 NVMe 规范打造了一条无翻译的直达路径。在新架构下,冗余的“双重转换”被彻底移除,I/O 请求的下发路径被优化为端到端的原生分发机制:
- 原生驱动接管: 对于被新架构接管的 NVMe 存储设备,上层文件系统产生的 I/O 请求不再经过传统的通用 Disk.sys 驱动,而是直接交由全新开发的专属驱动 NVMeDisk.sys 接管,在逻辑层直接生成原生的 NVMe 指令。
- 多队列直接分发: 指令从 NVMeDisk.sys 直接传递至存储端口驱动(Storport.sys)中的 StorMQ(存储多队列,Storage Multi-Queue)。StorMQ 在系统软件层面对齐了硬件侧的 NVMe 多队列架构,将指令直接投递至物理存储介质,该流程完全绕过了传统微型端口驱动(Miniport)的二次协议翻译层。
通过上述架构层面的精简,Windows Server 2025 实现了 I/O 路径的显著缩短。这种原生模式显著降低了 CPU 内核态在处理海量中断与并发请求时的调度与上下文切换开销。操作系统端的存储栈与现代PCIe 5.0 企业级NVMe SSD 硬件端的多队列机制实现完美匹配,底层硬件在数百万 IOPS 级别的真实并发潜能得以被完整释放。
实测解析:软硬全栈协同,彻底释放并发潜能
01.测试环境
为验证架构升级的实际收益,大普微使用具备极限并发 I/O 处理能力的 DapuStor R6101 PCIe 5.0 企业级 NVMe SSD 进行了一系列基准对照压测。
服务器平台:
- 处理器:单路 AMD EPYC 9124 16-Core Processor
- 内存:32GB DDR5-4800 内存
操作系统:
- Windows Server 2022 (OS Build 20348,使用传统存储栈)
- Windows Server 2025 (OS Build 26100,开启 Native NVMe 支持)
存储设备:
DapuStor R6101 系列企业级 NVMe SSD(型号:DPRE5104T0TL03T8000,规格:3.84TB / U.2 PCIe Gen5 x4 / TLC / 1 DWPD)
测试工具与参数: FIO 基准压测软件,版本号3.13
测试前置条件:在执行压测前,已对测试盘进行充分的持续写入预处理,确保所有测试数据均在硬盘达到稳态(Steady State)后抓取。
- 顺序读写:128K 区块大小 (Block Size) / 64 队列深度 (QD) / 1 个测试线程
- 随机读写:4K 区块大小 (Block Size) / 64 队列深度 (QD) / 16 个测试线程
02.测试结果
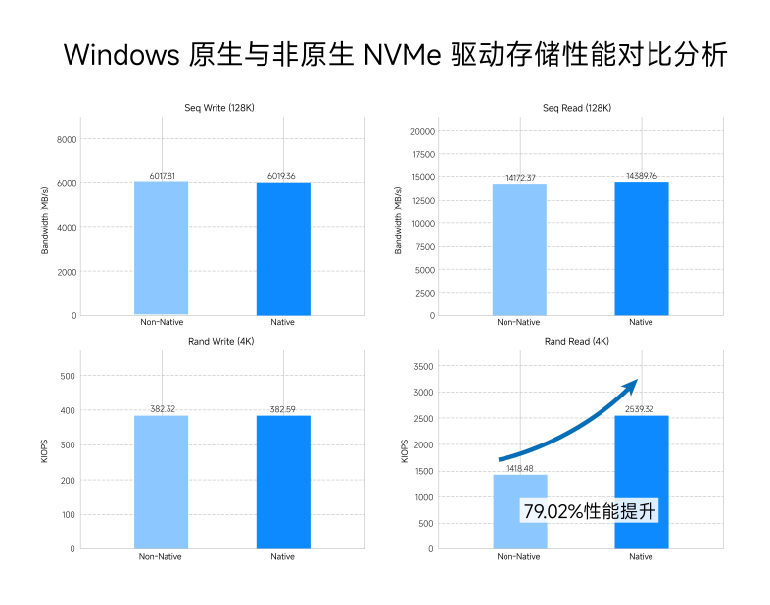
图1. Windows原生与非原生NVMe驱动存储性能对比结果
本次测试使用 FIO 工具,分别针对 128K 顺序读写和 4K 随机读写四种典型企业级负载场景进行了压测。具体测试结果如下:
- 128K 顺序写入:在使用 FIO 配置 128K 数据块进行顺序写入测试时,两种架构的吞吐性能基本一致,均稳定在 6 GB/s 左右,传统架构 6017.81 MB/s,原生架构 6019.36 MB/s。
- 128K 顺序读取:原生 NVMe 架构的吞吐量达到 14389.76 MB/s,较传统架构的14172.37 MB/s有微幅领先,但整体来看,两者在极致顺序拉取下的表现基本处于同一梯队。
- 4K 随机写入: 针对 4K 数据块的随机写入测试,传统架构取得 382.32 KIOPS,原生架构取得 382.59 KIOPS,两者性能表现高度一致。
- 4K 随机读取:在该项测试中,我们观察到了新架构带来的最为关键的性能突破。在使用 FIO 配置 4K 数据块进行高并发随机读取时,原生 NVMe 架构展现出了显著的优势:其 IOPS 从传统架构的 1418.48 KIOPS 大幅跃升至 2539.32 KIOPS,提升幅度高达 79.02%。这一实测数据与微软官方宣称的“提升约 80%”高度吻合。
在128K顺序读写以及 4K 随机写入场景中,两种架构的测试成绩均达到了DapuStor R6101 NVMe SSD的标称稳态性能。而在 4K 随机读取这一高并发场景下,原生NVMe架构的实测性能同样达到了该硬盘的物理标称值;相比之下,非原生架构的性能表现则存在显著差距。
这一现象表明,在面对海量随机 I/O 请求时,非原生的系统存储栈已经成为制约底层硬件性能发挥的瓶颈。而Windows Server 2025 的原生 NVMe 架构消除了协议转换带来的计算开销,让 DapuStor R6101 NVMe SSD极高的随机读取并发能力终于得以彻底释放,实现了性能的巨大提升。
业务赋能:构建 AI 时代高并发存储基石
在真实的业务场景中,4K 随机读取性能近 80% 的跃升,意味着系统能够更加高效地处理海量、碎片化的小文件请求。无论是传统数据库的复杂索引查找及碎片化检索,还是 AI 业务负载中的向量数据库相似性检索与特征节点遍历,其核心痛点都在于极高并发下的 I/O 响应延迟。DapuStor PCIe 5.0 SSD 与 Windows Server 2025 原生架构的深度结合,通过软硬件的底层协同,大幅提升了数据供给效率。