
加速AI模型训练:DapuStor SSD + BaM技术
在图和数据分析、推荐系统 、机器视觉等领域,通常需要利用 GPU进行多种多样的 AI 模型训练。在模型训练时,数据加载到显存的速度和效率是影响训练时间的关键因素。由于训练数据集的大小可能高达数十TB,远大于 GPU 内存(HBM),因此必须对完整的数据集进行拆分,并在模型训练程序的每次迭代过程中,及时向GPU交付指定的数据子集。要做到这一点,目前主要有两类方法:
1. 依靠CPU调度,从驱动器获取训练数据,再传递给GPU。
2. 使用更大的主机内存或 多个GPU 组成的内存池,把所有训练数据存放在内存中。
第一种方法涉及CPU和GPU同步的开销,第二种方法则非常昂贵。
BaM就是为解决这个问题而提出的。BaM(Big accelerator Memory)是一个软件框架,利用它GPU可以按需直接从驱动器获取训练数据,从而省去CPU的干预,同时节约成本。利用GPU线程的并行性、在GPU上运行的用户态 NVMe 驱动程序以及供程序使用的Cache接口,BaM能够最大限度地发挥现代NVMe SSD的高吞吐量和低延迟优势。
* BaM由英伟达™(NVIDIA®)、IBM、伊利诺伊大学香槟分校、布法罗大学组成的研究团队提出,在本文中我们使用DapuStor R5101,H5100 验证BaM的性能收益。
01 BaM的性能收益测试配置
我们使用IGB heterogeneous Large数据集测试了BaM在训练GNN(图神经网络)模型时的性能表现。GNN训练过程包括三个阶段:采样(sampling)、特征聚合(feature aggregation)和模型训练(training)。我们使用如下的配置来评估 GNN 训练在 3 个阶段所花费的时间。
测试方法是运行1100次迭代进行,每次迭代处理数据集中的一批节点特征值,记录最后100次迭代所花费的总时间(前1000次迭代作为系统的预热阶段)。
为评估BaM的性能收益,我们也做了基线测试用来做比较。在基线测试中,训练用的节点特征值存储在SSD上,同时Memory Map到主机内存。当运行在GPU上的模型训练程序需要读取训练数据时,先尝试从主机内存获取数据,如果无法直接在主机内存中找到有效数据,会触发操作系统的Page Fault 处理机制,通过CPU从SSD中读取原始数据。
02 搭载DapuStor SSD测试结果
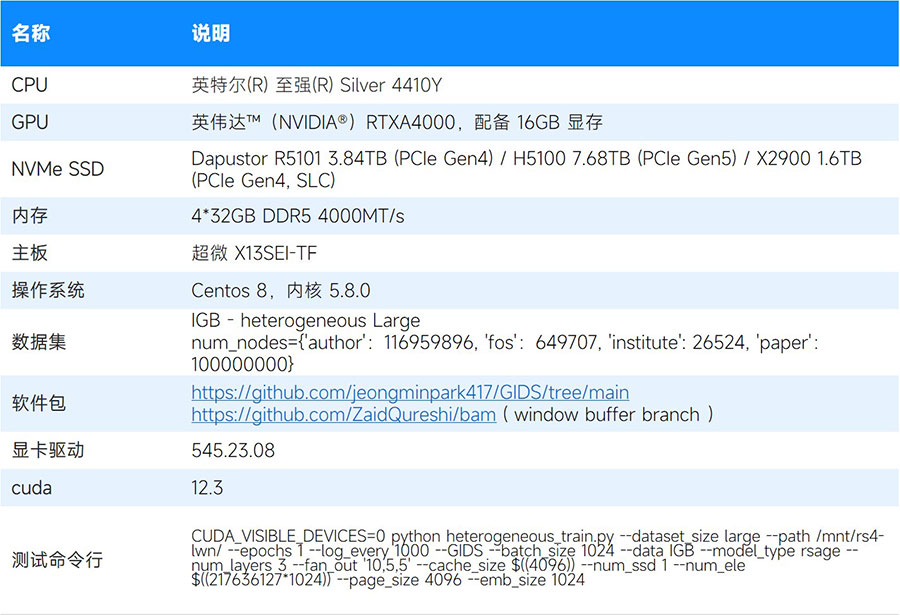
BaM 和基线测试
测试结果表明,与基线相比,采用BaM的模型训练端到端执行时间大大缩短。这一点在本次测试中使用的所有产品中都得到体现。如下图所示,时间单位为秒。从测试结果看,与基线相比使用BaM能将训练速度提升25倍以上。
* Baseline 的测试是基于R5101,但是在这种情况下 SSD 的型号对测试结果影响不大,软件开销是主要影响因素。
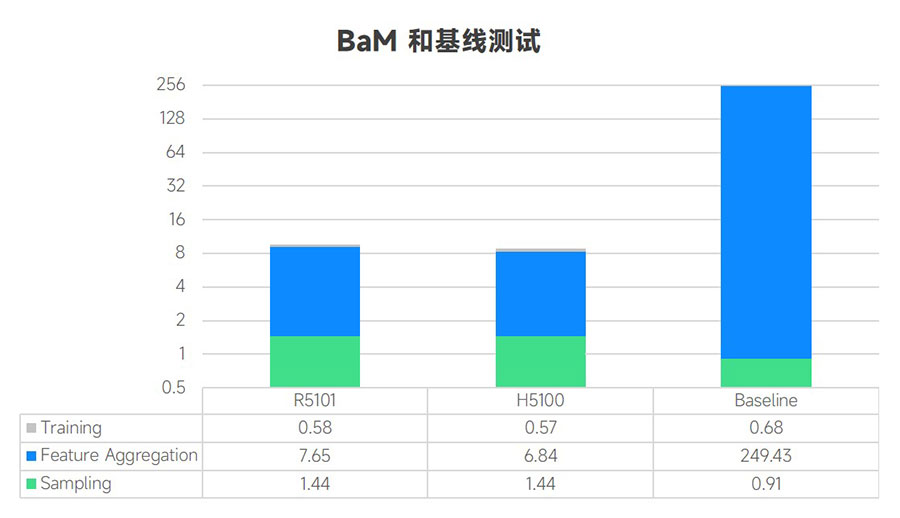
另一方面,我们发现:与基线相比,使用BaM时特征聚合(Feature Aggregation) 阶段的执行时间明显缩短。这是因为采样和模型训练是计算密集型的,BaM对这些步骤的改进不大。而特征聚合受到IO性能的影响,在这一步骤中IGB数据集的节点特征从 SSD读取到GPU。
从各阶段在总的执行时间中的占比角度看,BaM测试中用于特征聚合的时间比例远远低于基线测试,从99%降至77%。如下图:
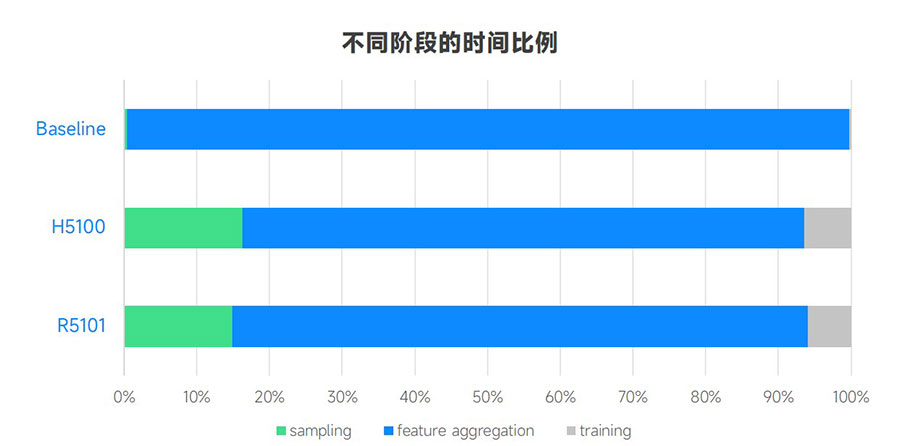
SSD数量的影响
如果在测试系统中增加一个SSD,BaM 就能利用并行性,将特征聚合的执行时间减少40%,而采样和训练阶段的执行时间变化不大。由于BaM支持使用多个NVMe SSD,因此随着系统中SSD数量的增加,性能会进一步提高。
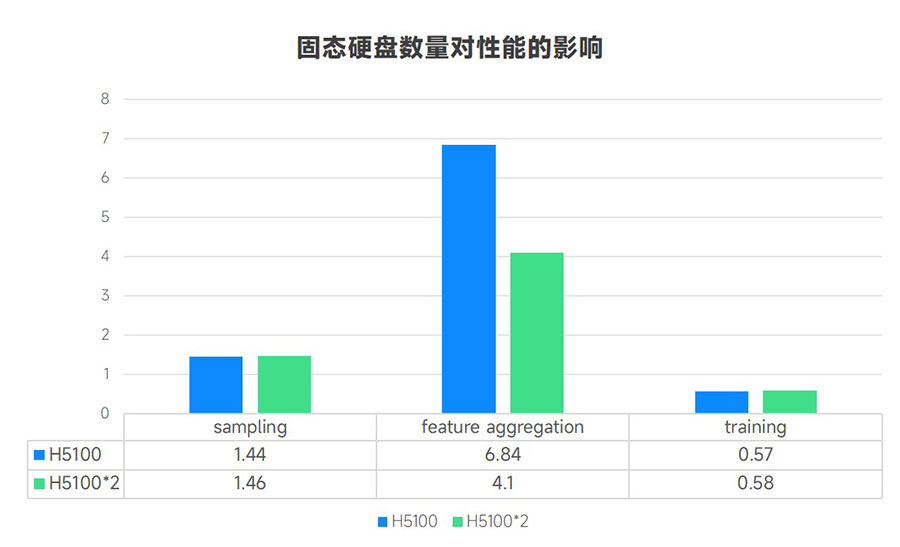
PCIe Gen5 接口的作用
在另一项测试中,我们将--batch_size 参数从1024 增加到4096,以便在程序运行中对SSD施加更大的IO压力,在实际项目中--batch_size 参数大小可能按需调整。测试结果表明,在更高的工作负载下PCIe Gen 5 接口的性能要优于 Gen4。
与 R5101(PCIe Gen 4接口)相比,H5100(PCIe Gen 5 接口)的特征聚合执行时间缩短了 18%。体现了PCIe Gen 5接口的优势。另外,在测试中观测到的IOPS约为 200 万,仍低于H5100的产品规格,显示了这一系统的性能仍有继续提升的可能。

03 使用 BaM技术+SSD,加速AI模型训练
ChatGPT的出现,引领了人工智能的新一轮创新浪潮。随着模型规模的快速增长,对算力,存储,电力都提出了更高的要求。如何提升AI大模型资源利用率,降低大模型的使用成本成为当前发展的重要议题。GPU 是当前AI 系统中的昂贵资源,在AI 模型训练中,因为等待数据而让GPU闲置会导致投资浪费。特别是在云环境中,GPU服务器按租用时间收费,缩短模型训练时间能够帮助企业大幅节省成本。
我们看到采用BaM软件,以DapuStor R5101和H5100 作为测试对象,该框架能够由GPU直接发起存储访问,充分利用 NVMe SSD 的高性能优势,减少人工智能训练中数据准备的时间,最大限度地提高 GPU资源利用率,将训练时间降低数十倍,展现了其在AI 领域的应用潜力。此外,它还表明PCIe Gen5 接口在这种需要高 IOPS 的应用场景中更具优势。
