SSD对AI推理中KV Cache的贡献与架构解析
随着大语言模型的飞速发展和智能体应用的普及,AI推理系统正面临着前所未有的算力与存储挑战。在Transformer架构中,KV Cache 作为存储历史计算状态的关键机制,对于提升推理性能、节省计算资源起着至关重要的作用。
然而,随着长上下文工作负载的激增,高昂的GPU显存成本正逐渐成为制约算力集群扩展的物理瓶颈。面对这一行业痛点,将庞大的 KV Cache 向更具性价比的外部存储介质进行卸载,已成为一种极具可行性的经济型解决方案。 本文将回归技术本源,剖析 KV Cache 在大模型推理中的运转机制,并结合大普微NVMe SSD,探讨如何为 AI 基础设施构建高性价比的存储方案。
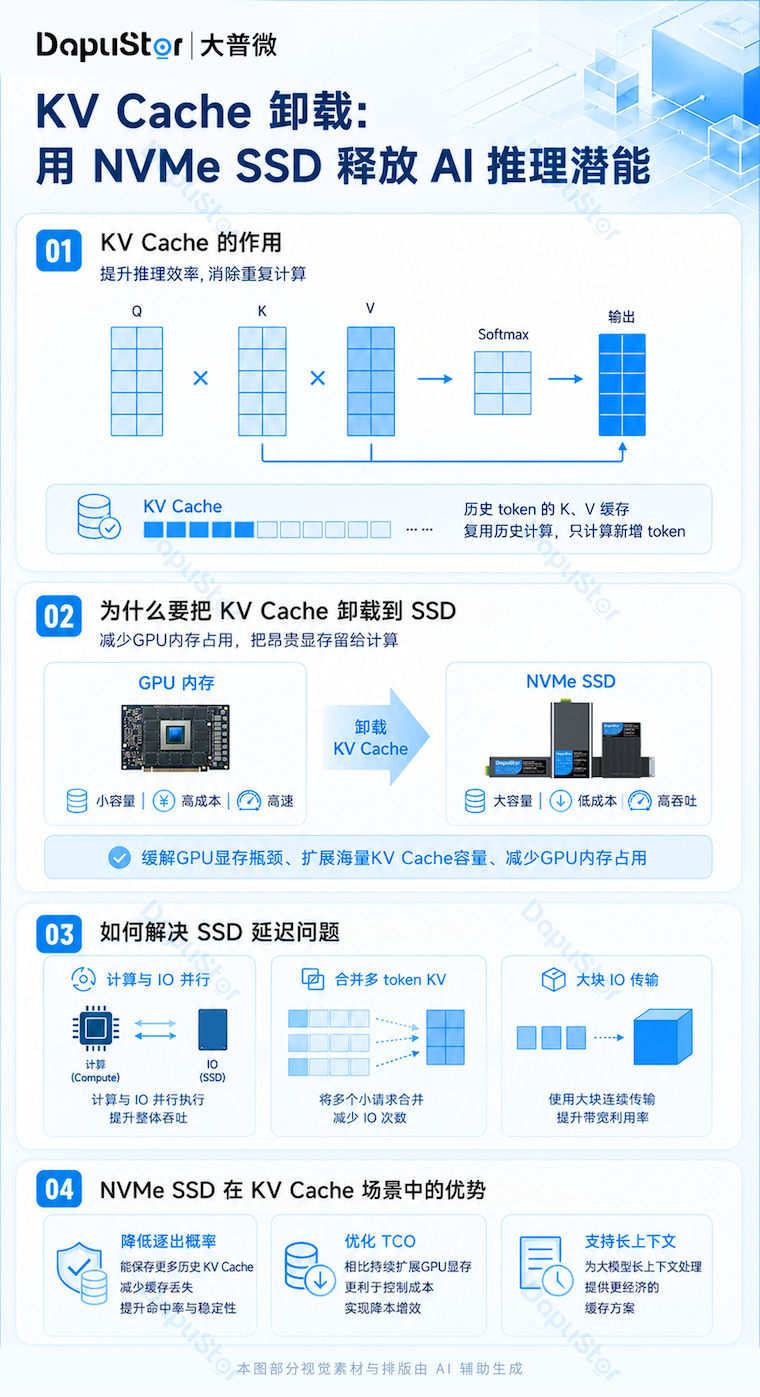
01 KV Cache 在 AI 推理中的作用
大语言模型在生成内容时,依赖多头注意力机制的矩阵运算,而计算多头注意力的关键是计算 K 和 V 矩阵,这就是KV Cache 发挥作用的地方。在计算时,系统需高频处理 K与 V矩阵。若无缓存机制,模型每次均需对整个长文本序列进行全局重算;而引入 KV Cache 后,系统即可将已计算的历史 KV 矩阵数据进行存储与直接复用。
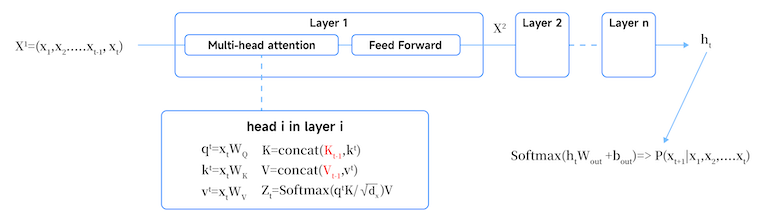
当新 Token 输入时,模型仅需计算新增特征,并与存储的历史 KV 数据拼接即可完成后续运算。通过彻底消除庞大的重复计算量,KV Cache 构筑了提升大模型推理效率的基础支撑。
02 KV Cache 重用可节省 GPU 资源
将历史 KV 矩阵存储并按需获取,可从计算和存储两个维度显著减轻 GPU 负载:
1.提高单个GPU的吞吐量
在 AI 推理项目的规划阶段,为了估算集群所需的 GPU 数量,常见方法是从小型配置的基准测试开始,获取延迟和吞吐量等约束条件下的性能指标,然后再外推至全规模配置。该公式可大致表述为:
所需 GPU 数量 = 目标吞吐量 / (小规模配置的吞吐量 × 利用率) × 小规模配置中的 GPU 数量
其中吞吐量可以用每秒token数来评估。
KV Cache复用通过消除冗余重算,从而缩短了响应时延(TTFT),这不仅加速了每个请求的处理,还腾出了处理更多请求的资源。
有一种观点认为,用户请求可能缺乏足够的共享上下文,导致 KV 缓存的复用效果不佳。然而,在实际工作负载中,上下文共享机制正变得愈发普遍。一个典型的场景是Agent 应用,用户可通过向 Openclaw 分配任务并分析其后端执行轨迹加以印证。例如:用户向 Openclaw 发送一条消息,要求其启动浏览器,访问 example.com,然后点击“了解更多”链接。尽管前端仅有一条消息输入,但从后端系统可以清晰观察到,Openclaw 实际上向 AI 模型高频发送了多条包含共享历史状态的并发请求,以协同完成该任务。



....
随着智能体应用的日益普及,以长历史上下文为特征的工作负载将逐渐盛行。
另一方面,与仅模拟完全随机请求的benchmark相比,更推荐使用带有共享上下文的 benchmark 来评估AI推理系统的吞吐量,并且测试环境中应该配置存储系统以提升吞吐量。vllm 社区推荐的multi-round QA 测试便是其中之一[1]。
2.将 KV Cache 从 GPU 内存中卸载
在系统规划设计中,提升吞吐量需增加批处理大小(即 GPU 集群处理的并发请求数量),但从并发请求的内存占用角度来看,GPU 内存大小是一个限制因素,而 KV Cache在其中占据了相当大的比例。
假设所有并发请求的KV cache都存储在GPU内存中,则经典MHA(多头注意力)算法在特定时间点产生的数据量可通过以下公式估算:
2 × B × S × L × H × D 其中B 为 batch size(并发请求数),S 为输入提示词中的 token 数,L 为大模型的层数,H 为多头注意力机制中的head 的数量,D 为每个head向量的维度。
随着请求长度不断增加和新请求的涌入,KV Cache 的大小最终会超过 GPU 内存的容量。尽管业内提出了如 DeepSeek 的 MLA(Multi-Head Latent Attention)等创新压缩方法来降低数据维度,但此类技术进步反过来会促使应用侧采用更长的序列甚至更大规模的部署。
因此,将 KV Cache 从 GPU 卸载到外部存储(如 NVMe SSD)以减少 GPU 内存占用,正受到行业内越来越多的关注。
03 解决使用SSD进行KV缓存的挑战
采用 NVMe SSD 承载海量 KV 数据虽然具备天然的容量优势,但必须克服数据读取延迟的物理瓶颈。得益于 AI 基础软件生态的演进,主流框架(如 vLLM 和 LMCache)的核心优化策略如下:
1.同时进行 IO 处理和模型计算
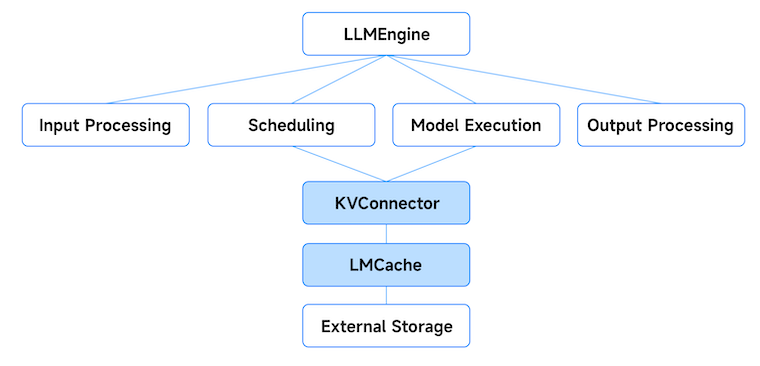
vllm 引擎的核心组件由 4 个部分组成:输入处理、调度、模型执行和输出处理。以下是 vllm 社区 [2] 中对这些组件功能的描述:
输入处理(tokenization):使用指定的分词器对输入文本进行分词处理。
调度:选择在每个步骤中处理哪些请求。
模型执行:管理大语言模型的执行,包括跨多个 GPU 的分布式执行。
输出处理:处理模型生成的输出,将语言模型输出的token解码为人类可读的文本。
vllm 提供 KVConnector 接口,任何实现 KV 缓存卸载的模块均可连接至该接口。LMCache 位于 vllm 与任何外部第三方存储系统(例如主机内存、本地磁盘、分布式存储)之间,从而解耦推理引擎后端,并为第三方外部存储系统提供标准接口。
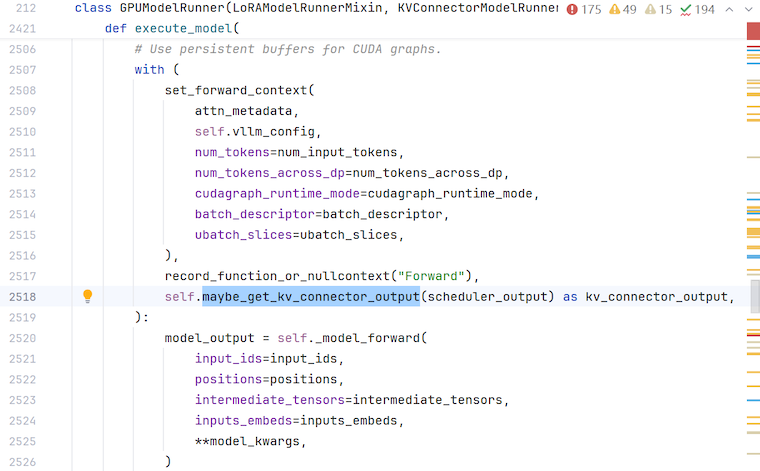
IO和计算操作的重叠是通过vllm的 scheduler 和 model_runner 组件之间的协作来实现的。
在每次调度操作中,调度器在选择待处理的请求的同时设置 KVConnector 的元数据,该元数据描述了后续将传输的 KV 数据。具体而言,此功能在 Scheduler.schedule 函数中实现。

当 model_runner 有机会执行请求时,它会同时发起后台 KV 数据传输。
2.合并多个 token 的 KV cache 以形成大块 IO
vLLM 和 LMCache 都具备将多个 token 的 KV Cache 数据打包传输的功能,这种设计旨在优化内存使用和IO效率。vLLM 采用 PagedAttention 方法默认以页为单位(16 tokens/页)管理 KV cache,该数值可通过命令行参数进行修改。LMCache 进一步扩展了范围,默认使用包含 256 个token的chunk,该配置可在配置文件 lmcache/v1/config.py 中进行调整。外部第三方存储系统可利用这种大块的chunk,生成对闪存极度友好的连续大 I/O 模式,最大化释放带宽潜能。
04 NVMe SSD 在 KV 缓存场景中的优势
在解决延迟和 IO 模式挑战的基础上,采用 NVMe SSD 卸载 KV Cache 的收益极其显著,这与大普微 R6 系列 SSD 的物理特性实现了深度契合:
1.最小化KV缓存逐出概率
如果系统能够尽可能多地存储历史 token 的 KV Cache,将有助于降低计算开销,因为随着时间的推移,丢失的KV Cache 可能会影响模型在长序列任务上的性能[3]。
随着单个驱动器的容量的提升,大普微目前R6060 系列单盘容量最高可达 245TB,使得构建一个具备海量容量的 KV 存储后端成为现实。
2.极致的存储成本优化
由于 KV Cache 复用技术对大语言模型输出的功能和正确性并不起关键作用(数据即使丢失也可由计算资源重算),因此在系统设计上存在降本需求。
随着 vLLM 和 LMCache 等软件将 I/O 模式优化为更适合 SSD 的形式,IO延迟被计算过程所隐藏,数据呈现“写入一次、读取多次”的特性。结合硬件从 PCIe Gen4 向 PCIe Gen5 的性能迭代,极具性价比的大普微 R6 系列 SSD 能够在保障系统稳定性的前提下,帮助数据中心显著降低 AI 推理的整体拥有成本。
前瞻布局构筑 AI 推理存储支撑
在 AI 推理领域,KV Cache 已成为系统架构中不可或缺的核心部分。从破解显存容量瓶颈以及优化整体部署成本的角度来看,将 KV Cache 卸载至外部存储正展现出极大的实用价值。随着 AI 基础软件生态的快速发展与持续优化,NVMe SSD 有望在这一前沿场景中得到越来越广泛的应用。
面对这一正在加速落地的行业需求,大普微早已布局的 PCIe Gen5 SSD,凭借其海量空间与极佳的成本效益,与 KV Cache 卸载的业务特性实现了完美契合。
[1] https://github.com/vllm-project/production-stack/tree/main/benchmarks/multi-round-qa
[2] https://github.com/vllm-project/vllm/blob/main/docs/design/arch_overview.md
[3] https://arxiv.org/abs/2412.19442